网络协议这块一直没有搞透彻,趁着苹果强制 ATS(Apimp Transport Security)未果,学习一下这方面的知识。
HTTP的构成
HTTP Request
http 请求主要分为三部分,如下图所示。request line,header 和 body,中间的CRLF为换行符。
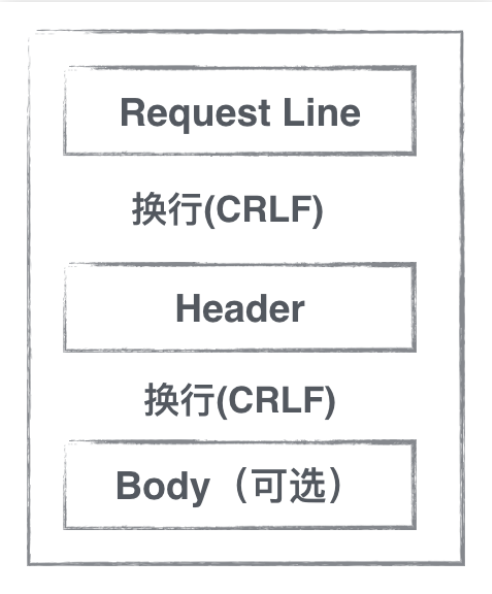
下面将以一个实际的 http 请求来详细看看其内部构造。假设我们的请求URL为:http://www.baidu.com/res/static/thirdparty/connect.jpg?t=1480992153433
Request Line
请求行的结构为:
1 | Request-Line = Method SP Request-URI SP HTTP-Version CRLF |
- Method:请求类型,例如
post/get。 - SP:分隔符,一般就是空格。
- Request-URI:对应上述请求为:
/res/static/thirdparty/connect.jpg?t=1480992153.564331。注意,Request-URI 也可以是带 host 的完整 uri。不带的话,就要在Header里添加 host。 - HTTP-Version:代表我们当前使用的版本,例如
HTTP/1.1 - CRLF:
CR对应回车键,LF对应换行键,合起来就是我们平常所说的\r\n。
所以上述请求的 Request-Line 的文本展示:
GET /res/static/thirdparty/connect.jpg?t=1480992153.564331 HTTP/1.1CRLF
Header
header 其本质上是一些文本键值对,一个典型的例子如下图所示:
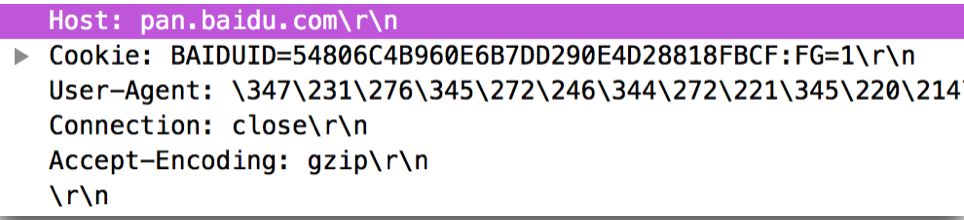
结构为:
1 | Key:空格ValueCRLF |
上面讲述 Request-URI 的时候,缺失的 Host 就以键值对的形式存在于 header 中,比如, Host: pan.baidu.com。
将若干个上述格式的键值对组合起来,就成了我们 HTTP 请求的完整 header。最后一个键值对之后再跟一个 CRLF,就表示我们的 header 结束了。
Body
body 里面包含请求的实际数据。
对于 Method=GET 的请求来说,body 体是为空的,Header 最后的两个 CRLF 就标识着请求的结尾。我们一般调用请求的业务参数是通过 Request Line 当中的 Request-URI 来传递的,比如上述请求中的 ?t=1480992153.564331,也就是 URI 的 query string 部分。这部分同样是以键值对的形式存在,不过是位于 Request Line 当中。
对于 Method=POST 的请求来说,实际的业务数据都存放于 body 当中。POST 请求可以根据 Header 中的 Content-Type 值,以不同的形式将数据保存在 body 体中。获取到请求后,可以仍然通过 Header 中的 Content-Length 值,读取固定长度的body体,直接传递给应用层
HTTP Response
response 的结构和 request 大致相似,不过是将 Request Line 换成了 Status Line 。

Status Line 的结构如下:1
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
Content-Type
Content-Type 用于指定内容类型,一般是指网页中存在的 Content-Type,Content-Type 属性指定请求和响应的 HTTP 内容类型。如果未指定 ContentType,默认为 text/html。
一些常见的 Content-Type:
- text/html
- text/plain
- text/css
- text/javascript
- application/x-www-form-urlencoded
- multipart/form-data
- application/json
- application/xml
前面几个都很好理解,都是 html,css,javascript 的文件类型,后面四个是POST 的发包方式。
那我们什么时候用 application/x-www-form-urlencoded,什么时候用 multipart/form-data 呢?大文件如文件图片用后者,小文件如键值对用前者。
Cache-Control 和 ETag 区别
Cache-Control 表示浏览器使用缓存,不像服务器发送请求。当 Url 不变时,如果资源没有超过 Expires 时间,则不进行服务器请求,直接使用浏览器缓存。
ETag 是请求资源文件的哈希值。在客户端请求后,服务端把资源文件的 md5 值作为 ETag 返回给浏览器。当浏览器下次请求的时候将这个 ETag 的值作为请求头字段 if-none-match 传给服务端,当资源文件不变的时候,服务端返回 304,当资源文件变化的时候,服务端将新的资源文件的 md5 值作为 ETag,连同资源文件返回给浏览器。
HTTP2.0 的改进
- header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
- 服务端推送(server push),同SPDY一样,HTTP2.0也具有server push功能。
- 多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
- 新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。HTTP2.0将文本转为二级制传输。如下图:

HTTPS
基本介绍
HTTP 协议传输的数据都是未加密的,也就是明文的,因此使用 HTTP 协议传输隐私信息非常不安全。比如运营商可以轻易劫持你的 http 请求,在 response 中注入 js代码(如网页上弹窗广告、流量球等),甚至是重定向。为了保证这些隐私数据能加密传输,于是网景公司设计了 SSL(Secure Sockets Layer)协议用于对 HTTP 协议传输的数据进行加密,从而就诞生了 HTTPS。之后对 SSL 进行了升级为 TLS(Transport Layer Security)。我们现在的 HTTPS 都是用的 TLS 协议。
一般来说 HTTPS 也需要进行 TCP 的三次握手,但是和 HTTP 不同的是,HTTPS 还需要进行 SSL 握手。这也就是其比 HTTP 在建立连接时慢的主要原因。
工作原理
总共分为以下几步:
- 浏览器将自己支持的一套加密规则发送给网站。
- 网站从中选出一组加密算法与 HASH 算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。
- 获得网站证书之后浏览器要做以下工作:
- 验证证书的合法性(颁发证书的机构是否合法,证书中包含的网站地址是否与正在访问的地址一致等),如果证书受信任,则浏览器栏里面会显示一个小锁头,否则会给出证书不受信的提示。
- 如果证书受信任,或者是用户接受了不受信的证书,浏览器会生成一串随机数的密码,并用证书中提供的公钥加密。
- 使用约定好的HASH计算握手消息,并使用生成的随机数对消息进行加密,最后将之前生成的所有信息发送给网站。
- 网站接收浏览器发来的数据之后要做以下的操作:
- 使用自己的私钥将信息解密取出密码,使用密码解密浏览器发来的握手消息,并验证HASH是否与浏览器发来的一致。
- 使用密码加密一段握手消息,发送给浏览器。
- 浏览器解密并计算握手消息的HASH,如果与服务端发来的HASH一致,此时握手过程结束,之后所有的通信数据将由之前浏览器生成的随机密码并利用对称加密算法进行加密。
这里浏览器与网站互相发送加密的握手消息并验证,目的是为了保证双方都获得了一致的密码,并且可以正常的加密解密数据,为后续真正数据的传输做一次测试。
其中非对称加密算法用于在握手过程中加密生成的密码,对称加密算法用于对真正传输的数据进行加密,而 HASH 算法用于验证数据的完整性。由于浏览器生成的密码是整个数据加密的关键,因此在传输的时候使用了非对称加密算法对其加密。非对称加密算法会生成公钥和私钥,公钥只能用于加密数据,因此可以随意传输,而网站的私钥用于对数据进行解密,所以网站都会非常小心的保管自己的私钥,防止泄漏。
为什么不直接全程使用非对称加密算法进行数据传输?这个问题的答案是因为非对称算法的效率对比起对称算法来说,要低得多得多;因此往往只用在HTTPS的握手阶段。
证书的验证过程
证书以证书链的形式组织,在颁发证书的时候首先要有根CA机构颁发的根证书,再由根CA机构颁发一个中级CA机构的证书,最后由中级CA机构颁发具体的SSL证书。我们可以这样理解,根CA机构就是一个公司,根证书就是他的身份凭证,每个公司由不同的部门来颁发不同用途的证书,这些不同的部门就是中级CA机构,这些中级CA机构使用中级证书作为自己的身份凭证,其中有一个部门是专门颁发SSL证书,当把根证书,中级证书,以及最后申请的SSL证书连在一起就形成了证书链,也称为证书路径。在验证证书的时候,浏览器会调用系统的证书管理器接口对证书路径中的所有证书一级一级的进行验证,只有路径中所有的证书都是受信的,整个验证的结果才是受信。操作系统在安装过程中会默认安装一些受信任的CA机构的根证书。
SSL劫持
SSL 劫持也就是 SSL 证书欺骗攻击,攻击者为了获得 HTTPS 传输的明文数据,需要先将自己接入到浏览器与目标网站之间(中间人),在传输数据的过程中,替换目标网站发给浏览器的证书,之后解密传输中的数据,简单的图示如下:
[浏览器] <======> [目标网站] (正常情况)
[浏览器] <======> 中间人 <======> [目标网站] (中间人攻击)
中间人攻击最好的环境是在局域网中,局域网中所有的计算机需要通过一个固定的出口(网关)来接入互联网,因此攻击者只需要在局域网中实施一次中间人攻击就可以顺利的截获所有计算机与网关之间传输的数据。
中间人攻击(Man-in-the-Middle Attack,缩写 MITM)。
抓包工具 mitmproxy 使用
mitmproxy 是一款命令行抓包工具,它除了可以抓包查看 http/https 请求,还可以拦截并修改 request 或者 response。
安装
1 | brew install mitmproxy |
配置
手机和电脑在同一局域网下,设置手机的 http 代理。服务器为电脑当前的 ip,如 192.168.3.10;端口可任意设置,一般设置为8080。网络环境配置好后,在终端输入 mitmproxy -p 8080,进入抓包模式。
如果想要抓取 https 的包,需要进一步配置。用 iPhone 打开 Safari 浏览器并输入 mitm.it,这时你会看到如下页面,选择对应平台并安装证书,安装完成后就可以抓 https 的包了。注意,用浏览器打开时需要已经在抓包模式,否则是无法看到上述页面的。
抓包软件相当于在用户和服务器间增加了一个中间人。安装抓包软件的证书,这样中间人就可以获得用户端生成的密钥,就能够解密用户和服务器间的信息。注意,一定不可随意下载信任不明的证书

使用
随便打开一个 app,就可以看到如下的一个请求列表。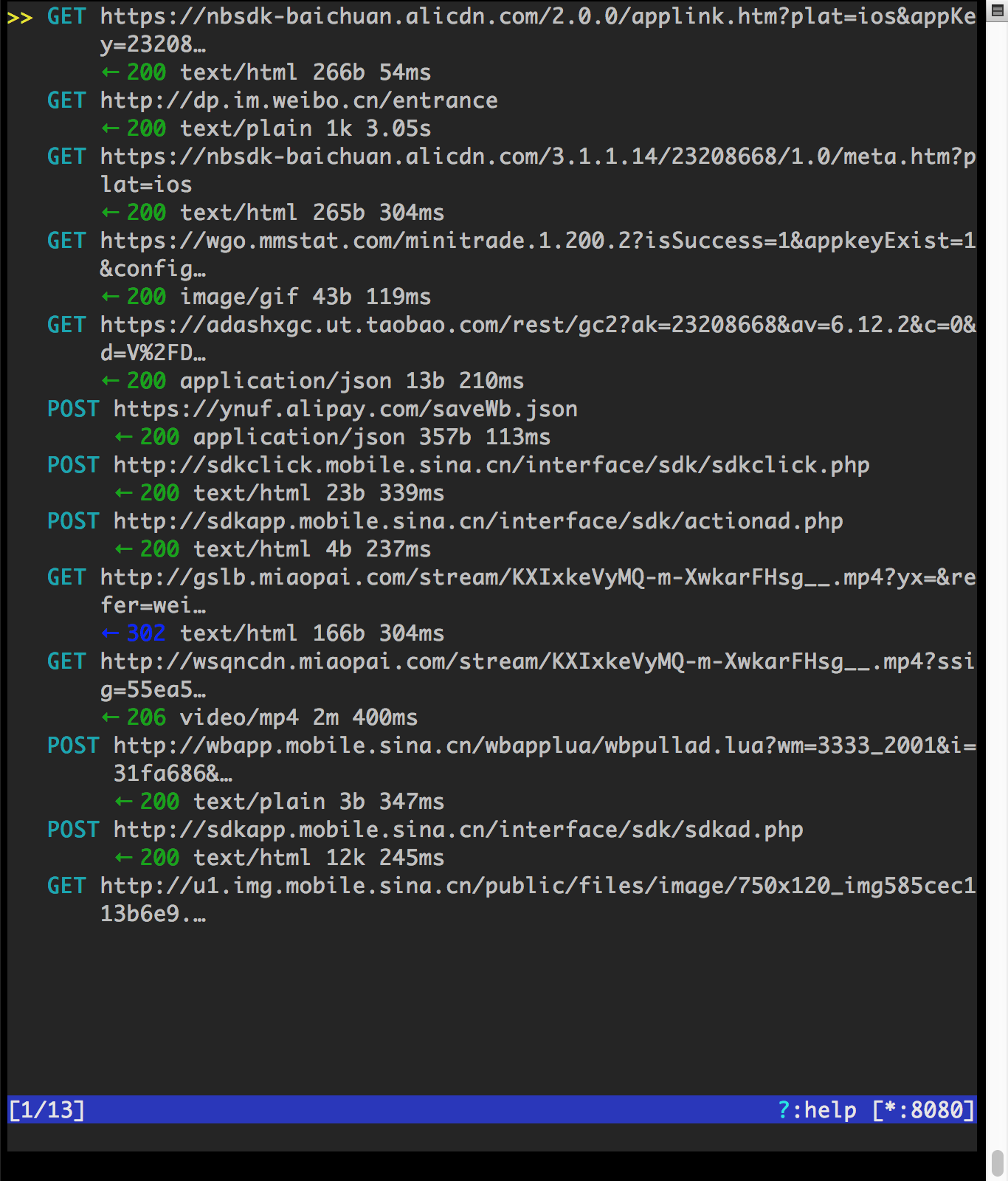
常用快捷键:
- enter: 查看详细请求
- Tab: 切换顶部导航栏
- z: 清空列表
- f: 过滤请求。可以参照帮助中的 Filter expression 对过滤关键字进行编辑。删除过滤就是将过滤关键字清空。其实还可以有更多过滤方式,包括过滤指定的 header,指定的 body,过滤请求、回复等。具体参见文档
- d: 删除请求
- h: 显示所有帮助
- m: 改变请求返回实体的类型。比如把 raw 改为 json
除了快捷键,我们可以按住 command 点击 url 来在浏览器中查看网页信息。可以按住 command+option+fn 然后选中信息
拦截
输入 i 设置拦截,再输入 ~s 进入 response 拦截模式,~q 进入 request 拦截模式。如果不想拦截了。再次输入 i 将刚才设置的参数清空即可。也可以键入 I 表示暂停拦截。
设置拦截后,拦截下来的请求为红色。这时 Enter 进入后 再按 e 就可以修改 request 或者 response,会先让你选择修改哪一部分,一般都是修改返回的数据对应于里面的 raw。修改时是用 vim 进行编辑的,修改完成后按 a 将请求放行,如果要放行所有请求输入 A 即可。
中文字符无法显示
中文字符无法显示其实是终端的问题。我们要修改 .zshrc,在最底部添加下面的代码:
1 | export LC_ALL=en_US.UTF-8 |
然后重启,就可以看到中文字符了。
iOS 模拟器抓包
为模拟器抓包需要设置网络代理为本机,勾选 HTTP 代理和 HTTPS 代理:

还要为模拟器配置 SSL 证书。配置证书相对麻烦。首先进入 ~/.mitmproxy目录,这个目录下有五六个证书,其中一个是符合要求的。需要下载一个 python 脚本 来导入证书。下载后执行:
1 | ./iosCertTrustManager.py -a mitmproxy-ca-cert.pem |
这个脚本只能导入 pem 格式的证书。执行时会问你是否将其添加到某个模拟器中,按 y 即可。添加成后需要重启模拟器就能够抓取 https 的包了。
模拟器抓包提示Certificate Verification Error for www.xxxx.com: unable to get local issuer certificate
使用:
1 | mitmproxy -p 8080 --ssl-insecure --set block_global=false |
忽略安全校验